04 - Structured Streaming
Structured Streaming in Databricks
Structured Streaming is a powerful feature of Apache Spark, integrated into Databricks, that enables scalable and fault-tolerant stream processing. It allows users to process streaming data as if it were a static table, providing a seamless experience for handling continuously evolving datasets.
Data Stream
A data stream is any data source that grows over time, such as new log files, database updates captured in Change Data Capture (CDC) feeds, or events queued in messaging systems like Kafka.
- Processing Approaches:
- Traditional Approach: Reprocess the entire dataset with each update.
- Incremental Approach: Use custom logic to capture only new data since the last update, which is efficiently handled by Spark Structured Streaming.
Spark Structured Streaming
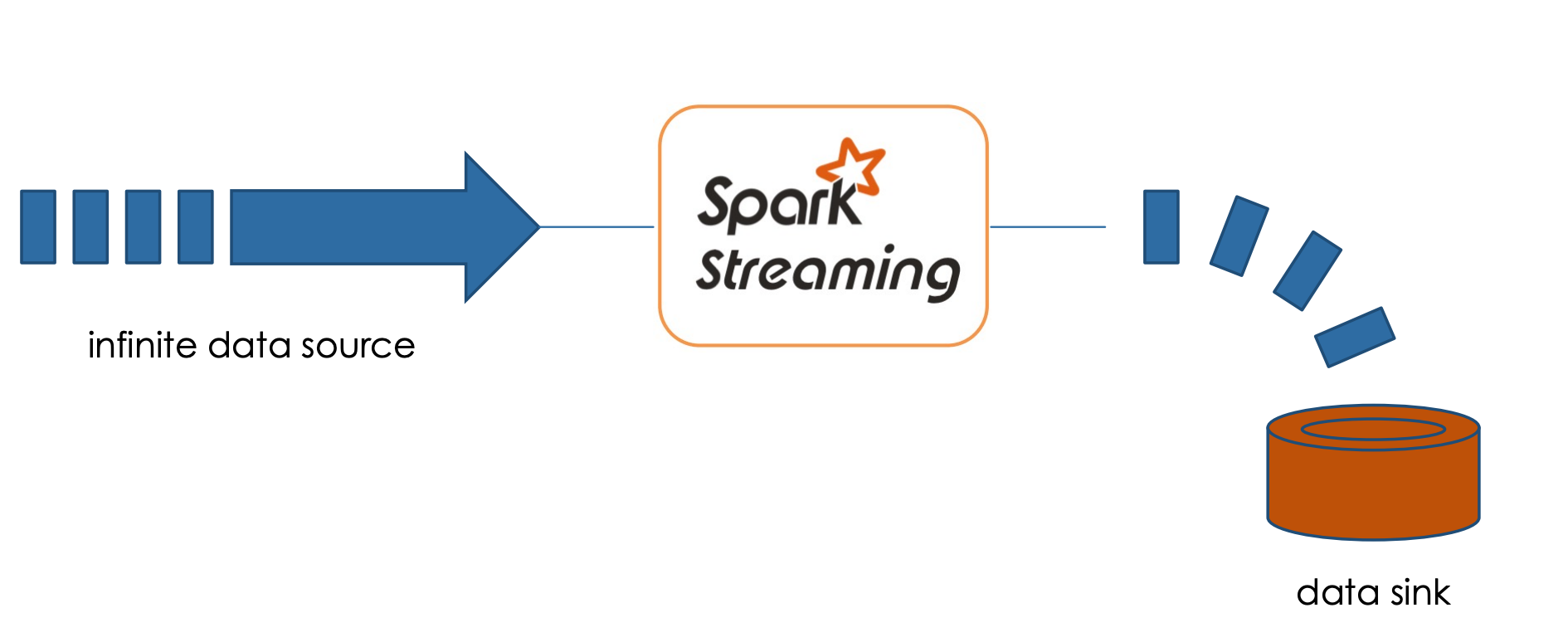
- Scalable Engine: It allows querying an infinite data source and incrementally persisting results into a data sink (e.g., files, tables).
- Table Abstraction: Treats streaming data as an “unbounded” table, making it easy to interact with new data as if appending rows to a static table.
Integration with Delta Lake
- Delta Tables: Delta Lake is well-integrated with Spark Structured Streaming. Using
spark.readStream(), you can query a Delta table as a stream source, processing existing and new data seamlessly.
(spark.readStream
.table("books")
.createOrReplaceTempView("books_streaming_tmp_vw")
)
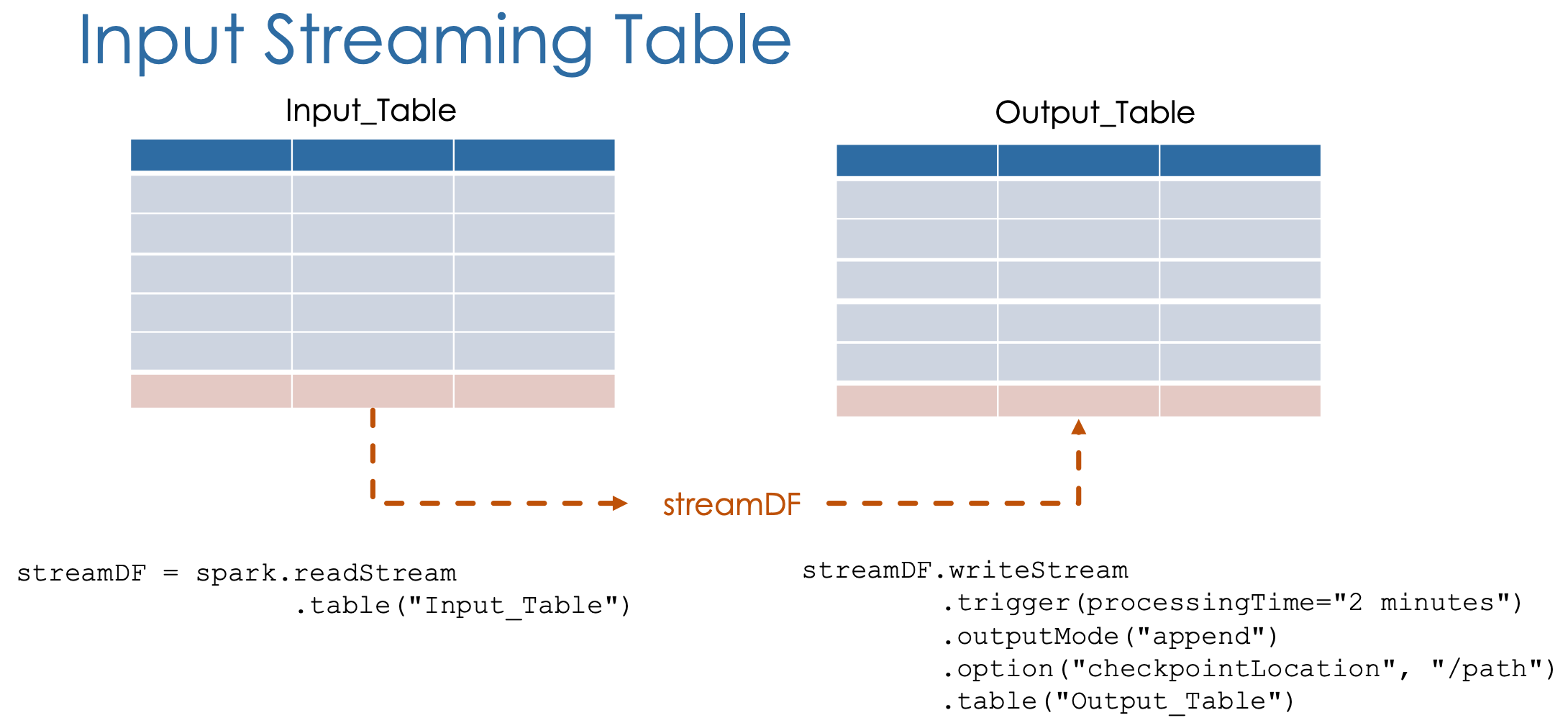
Streaming Queries
- DataFrame API: Transform streaming data frames using the same operations as static data frames.
- Output Persistence: Use
dataframe.writeStreamto write results to durable storage. Configure the output with:- Trigger Intervals: Specify when to process new data (default is every 0.5 seconds). Options include fixed intervals (e.g., every 5 minutes),
triggerOnce, oravailableNow.
- Trigger Intervals: Specify when to process new data (default is every 0.5 seconds). Options include fixed intervals (e.g., every 5 minutes),
streamDF.writeStream
.trigger(processingTime="2 minutes")
.outputMode("append")
.option("checkpointLocation", "/path")
.table(”Output_Table")
- Output Modes:
- Append Mode: Default mode; appends new rows to the target table.
- Complete Mode: Recalculates and overwrites the target table with each batch.
Checkpointing and Fault Tolerance
- Checkpoints: Store the current state of a streaming job to cloud storage, allowing resumption from the last state in case of failure. Each streaming write requires a separate checkpoint location.
Processing Guarantees
- Write-ahead Logs: Record the offset range of data processed during each trigger interval, ensuring reliable tracking of stream progress.
- Exactly Once Semantics: Achieved through repeatable data sources and idempotent sinks, ensuring no duplicates in the sink even under failure conditions.
Unsupported Operations
- Limitations: Some operations, like sorting and deduplication, are complex or logically infeasible with streaming data. Advanced methods like windowing and watermarking can help address these challenges.
Structured Streaming in Databricks provides a robust framework for processing streaming data, offering scalability, fault tolerance, and ease of use by abstracting streams as tables.
Incremental Data Ingestion From Files
- Loading new data files encountered since the last ingestion
- Reduces redundant processing
Auto Loader
Auto Loader is a feature in Databricks that simplifies the ingestion of large volumes of data files. It efficiently processes new files as they arrive in cloud storage.
- Scalable and Efficient: Handles billions of files and supports near real-time ingestion.
- Checkpointing: Stores metadata of discovered files to ensure exactly-once guarantees.
Example: Using Auto Loader with SparkSQL

(spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "parquet")
.option("cloudFiles.schemaLocation", "dbfs:/mnt/demo/orders_checkpoint")
.load(f"{dataset_bookstore}/orders-raw")
.writeStream
.option("checkpointLocation", "dbfs:/mnt/demo/orders_checkpoint")
.table("orders_updates")
)
-- Using Auto Loader to create a streaming table from CSV files
CREATE OR REFRESH STREAMING TABLE customers
AS SELECT * FROM cloud_files("/databricks-datasets/retail-org/customers/", "csv", map("delimiter", ",", "header", "true"));
COPY INTO Command
The COPY INTO command is used for idempotent and incremental loading of new data files into Delta tables.
- Efficient for Small Volumes: Best for thousands of files.
- SQL Syntax: Simple and straightforward to use.
Example: COPY INTO with SparkSQL
-- Loading data into a Delta table using COPY INTO
COPY INTO my_table
FROM '/path/to/files'
FILEFORMAT = CSV
FORMAT_OPTIONS ('delimiter' = ',', 'header' = 'true')
COPY_OPTIONS ('mergeSchema' = 'true');
Difference between Auto Loader and COPY INTO command
Here is a table summarizing the main differences between Auto Loader and COPY INTO:
| Feature/Aspect | Auto Loader | COPY INTO |
|---|---|---|
| Use Case | Designed for continuous, scalable, and efficient ingestion of large volumes of files. | Ideal for batch ingestion of smaller datasets or incremental appends. |
| Performance | Supports high scalability with features like file notification mode for large directories/files. | Best suited for smaller numbers of files (e.g., thousands or less) in directory listing mode. |
| Incremental Processing | Automatically tracks and processes new files incrementally using Structured Streaming. | Tracks ingested files to ensure idempotency but does not natively support continuous streaming. |
| Schema Management | Requires a schema location to store inferred schemas for faster restarts and schema stability. | Can infer schema directly during ingestion but does not require a schema location. |
| Transformation Support | Limited to transformations supported by Structured Streaming. | Supports simple transformations like column reordering, omission, and type casting during load. |
| Error Handling | Advanced error handling with automatic retries and recovery mechanisms. | Basic error handling with validation options for previewing data before ingestion. |
| Latency | Suitable for near real-time streaming ingestion with low latency. | Primarily used for batch ingestion; not optimized for low-latency use cases. |
| Configuration Complexity | Requires configuration of triggers, schema location, and optional file notification services. | Simple SQL-based command; minimal configuration required. |
| File Format Support | Supports multiple file formats via cloudFiles source (e.g., CSV, JSON, Parquet). |
Also supports various formats (e.g., CSV, JSON, Parquet) with explicit format options in the command. |
| Cost Efficiency | More cost-effective for large-scale streaming pipelines due to optimized resource usage. | Cost-effective for scheduled batch processing or smaller datasets with predictable loads. |
In summary:
- Use Auto Loader when working with large-scale data pipelines requiring continuous ingestion and scalability.
- Use COPY INTO for simpler batch ingestion tasks or when SQL-based workflows are preferred.