01 - Partitioning Delta Lake Table
Partitioning Delta Lake tables is a crucial technique for optimizing data management and query performance in a data lakehouse environment
What is Partitioning?
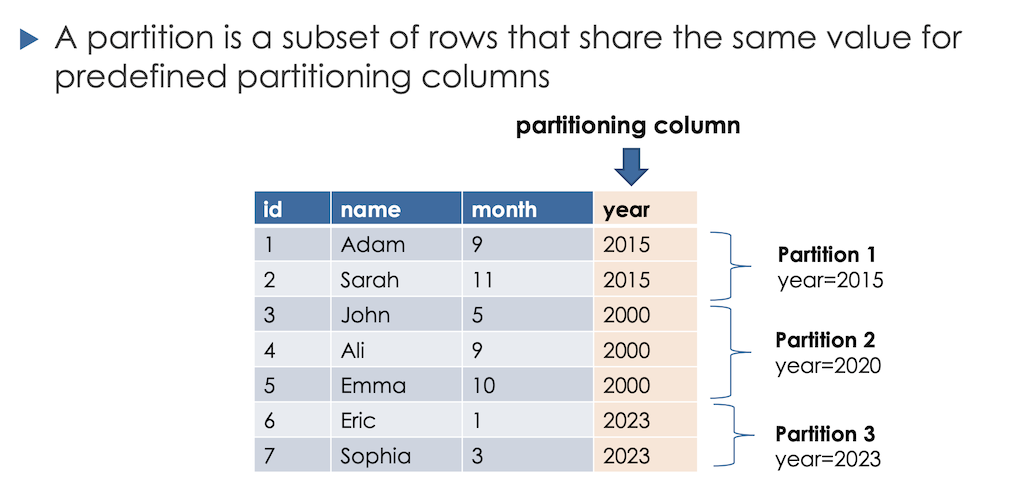
Partitioning is a method of dividing a large dataset into smaller, more manageable pieces based on the values of one or more columns. Each piece, or partition, is stored separately, which can significantly improve query performance and data management.
How Partitioning Works in Delta Lake
-
Choosing Partition Columns The choice of partition columns is critical. Typically, columns with high cardinality (many unique values) are not ideal for partitioning because they can lead to a large number of small files, which can degrade performance. Instead, choose columns with lower cardinality that are frequently used in query predicates.
-
Creating a Partitioned Table When creating a Delta Lake table, you can specify the partition columns. For example:
CREATE TABLE sales_data
USING DELTA
PARTITIONED BY (year, month)
AS SELECT * FROM raw_sales_data;
In this example, the table is partitioned by year and month, meaning each partition will contain data for a specific year and month.


Best Practices for Partitioning
Balance Partition Size: Aim for a balance between too many small partitions and too few large partitions. Ideally, partitions should be large enough to leverage parallel processing but not so large that they become inefficient. Use Date Columns: Date columns are often a good choice for partitioning because they are commonly used in queries and typically have a natural hierarchy. Monitor and Adjust: Regularly monitor query performance and adjust partitioning strategies as data and query patterns evolve. Leverage Delta Lake Features: Use Delta Lake’s built-in features like Z-Ordering (a technique to colocate related information in the same set of files) to further optimize partitioned tables.