01 - Kubernetes Architecture
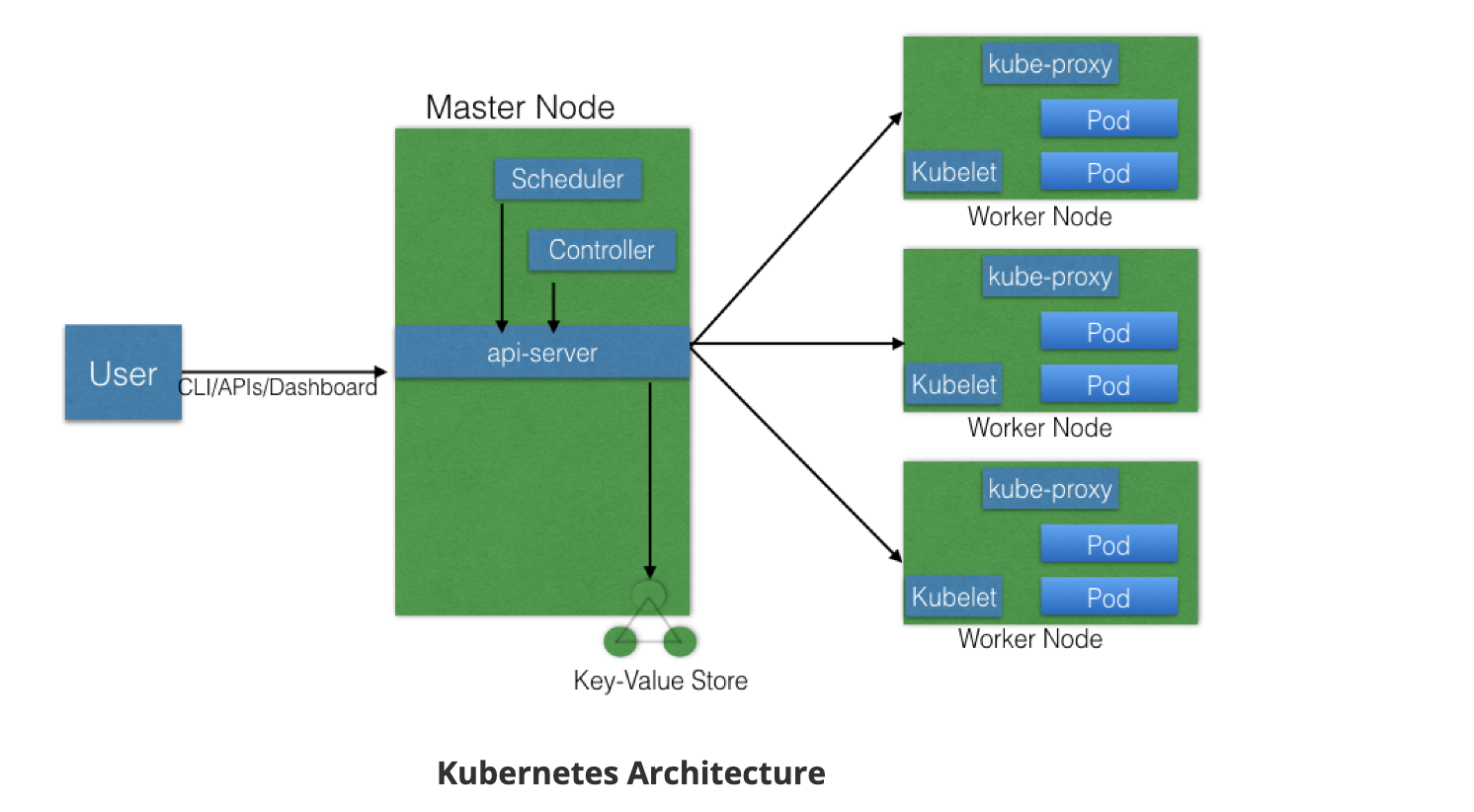
At a very high level, Kubernetes has the following main components
- One ore more master nodes
- One or more worker nodes
- Distributed key-value store, such as etcd
Master Node
The master node provides a running environment for the control plane responsible for managing the state of a Kubernetes cluster, and it is the brain behind all operations inside the cluster. The control plane components are agents with very distinct roles in the cluster’s management. In order to communicate with the Kubernetes cluster, users send requests to the master node via a Command Line Interface (CLI) tool, a Web User-Interface (Web UI) Dashboard, or Application Programming Interface (API).
Master Node Components
- API Server
- Scheduler
- Controller managers
- etcd
Master Node Components: API Server
All the administrative tasks are coordinated by the kube-apiserver, a central control plane component running on the master node. The API server intercepts RESTful calls from users, operators and external agents, then validates and processes them. During processing the API server reads the Kubernetes cluster’s current state from the etcd, and after a call’s execution, the resulting state of the Kubernetes cluster is saved in the distributed key-value data store for persistence. The API server is the only master plane component to talk to the etcd data store, both to read and to save Kubernetes cluster state information from/to it - acting as a middle-man interface for any other control plane agent requiring to access the cluster’s data store.
The API server is highly configurable and customizable. It also supports the addition of custom API servers, when the primary API server becomes a proxy to all secondary custom API servers and routes all incoming RESTful calls to them based on custom defined rules.
Master Node Components: Scheduler
The role of the kube-scheduler is to assign new objects, such as pods, to nodes. During the scheduling process, decisions are made based on current Kubernetes cluster state and new object’s requirements. The scheduler obtains from etcd, via the API server, resource usage data for each worker node in the cluster. The scheduler also receives from the API server the new object’s requirements which are part of its configuration data. Requirements may include constraints that users and operators set, such as scheduling work on a node labeled with disk==ssd key/value pair. The scheduler also takes into account Quality of Service (QoS) requirements, data locality, affinity, anti-affinity, taints, toleration, etc.
Master Node Componets: Controller Managers
The controller managers are control plane components on the master node running controllers to regulate the state of the Kubernetes cluster. Controllers are watch-loops continuously running and comparing the cluster’s desired state (provided by objects’ configuration data) with its current state (obtained from etcd data store via the API server). In case of a mismatch corrective action is taken in the cluster until its current state matches the desired state.
Master Node Components: etcd
etcd is a distributed key-value data store used to persist a Kubernetes cluster’s state. New data is written to the data store only by appending to it, data is never replaced in the data store. Obsolete data is compacted periodically to minimize the size of the data store.
Out of all the control plane components, only the API server is able to communicate with the etcd data store.
Worker Node
A worker node provides a running environment for client applications. Though containerized microservices, these applications are encapsulated in Pods, controlled by the cluster control plane agents running on the master node. Pods are scheduled on worker nodes, where they find required compute, memory and storage resources to run, and networking to talk to each other and the outside world. A Pod is the smallest scheduling unit in Kubernetes. It is a logical collection of one or more containers scheduled together.
Worker Node Components
A worker node has the following components:
- Container runtime
- kubelet
- kube-proxy
- Addons for DNS, Dashboard, cluster-level monitoring and logging.
Worker Node Component: Container Runtime
Although Kubernetes is described as “container orchestration engine”, it does not have the capability to directly handle containers. In order to run and manage a container’s lifecycle, Kubernetes requires a container runtime on the node where a Pod and its containers are to be scheduled. Docker is the most widely used container runtime with Kubernetes.
Worker Node Components: kubelet
The kubelet is an agent running on each node and communicates with the control plane components from the master node. It receives Pod definitions, primarily from the API server, and interacts with the container runtime on the node to run containers associated with the Pod. It also monitors the health of the Pod’s running containers.
The kubelet connects to the container runtime using Container Runtime Interface (CRI). CRI consists of protocol buffers, gRPC API and libraries.
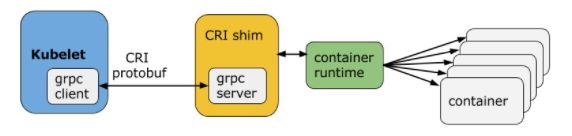
Worker Node Components: kube-proxy
The kube-proxy is the network agent which runs on each node responsible for dynamic updates and maintenance of all networking rules on the node. It abstracts the details of Pods networking and forwards connection requests to Pods.
Worker Node Components: Addons
Addons are cluster features and functionality not yet available in Kubernetes, therefore implemented through 3rd-party pods and services.
- DNS - cluster DNS is a DNS server required to assign DNS records to Kubernetes objects and resources
- Dashboard - a general purposed web-based user interface for cluster management
- Monitoring - collects cluster-level container metrics and saves them to a central data store
- Logging - collects cluster-level container logs and saves them to a central log store for analysis.
Networking Challenges
Container to Container Communication inside Pods
Making use of the underlying host operating system’s kernel features, a container runtime creates an isolated network space for each container it starts. On Linux, that isolated network space is referred to as a network namespace. A network namespace is shared across containers, or with the host operating system.
When a Pod is started, a network namespace is created inside the Pod, and all containers running inside the Pod will share that network namespace so that they can talk to each other via localhost.
Pod-to-Pod Communication Across Nodes
Kubernetes uses “IP-per-Pod” model to ensure Pod-to-Pod communication, just as VM are able to communicate with each other. Containers are integrated with the overall Kubernetes networking model through the use of the Container Network Interface (CNI)
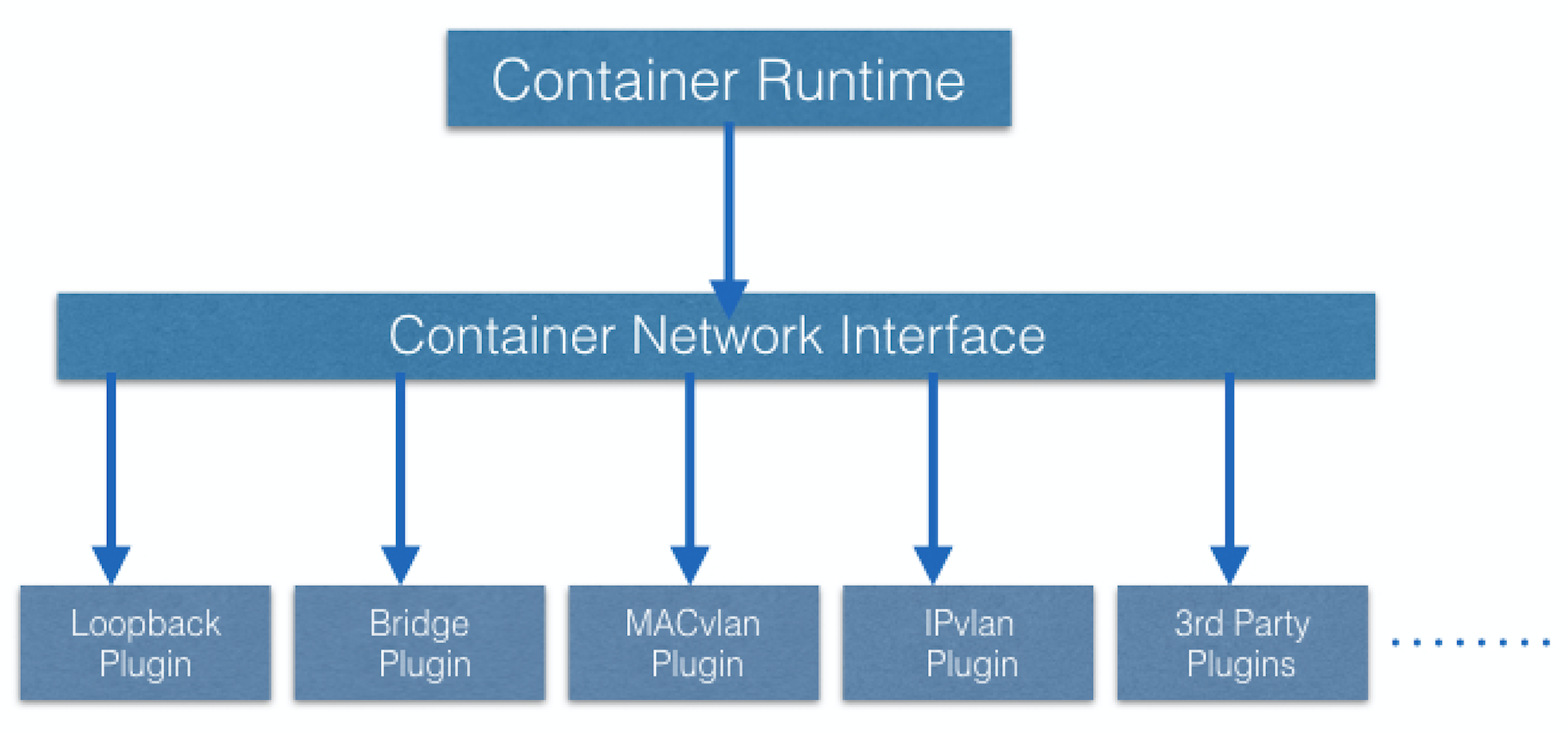
Pod-to-External World Communication
Kubernetes enables external accessibility through services, complex constructs which encapsulate networking rules definitions on cluster nodes. By exposing services to the external world with kube-proxy, applications become accessible from outside the cluster over a virtual IP.